My thoughts on Jenkins pipelines
Before Jenkins pipelines, all job configuration was stored as XML on the server, and only configurable via the web dashboard. There are a number of limitations to this approach. A few that come to mind are:
-
Access to configuration is limited - Either your developers are unable to modify job configurations, or your developers need administrative access to relevant jobs and an understanding of how to configure them.
-
Code and configuration are not synchronised - Changes to your application that require tweaks to your job configurations need to be carefully planned so that build failures aren’t caused between landing these changes and reconfiguring the associated jobs.
-
Configuration changes have no audit trail - There’s no history of changes to job configurations, and no easy way to revert these changes. I’ve found the JobConfigHistory plugin does help to resolve some of this limitation.
-
Experimentation is difficult - It’s not possible to experiment with changes to job configurations without creating a temporary duplicate job.
Pipelines solve all of these issues, while also providing many more benefits such as parallel build steps, pausing for input, and recovery from restarts. While I’ve found that there are still a few rough edges to pipelines, the advantages have far outweighed these costs, and I’m encouraged by the pace that improvements are being worked on.
If you’re not already familiar with Jenkins pipelines, the premise is simple.
All you need is to create a Jenkinsfile in the root of your project
repository, and configure your build as a series of steps in a domain-specific
language based on the Groovy programming language. Then in Jenkins you
create a pipeline, which needs to know where your repository exists, and a
small subset of the configuration from a traditional job such as name,
parameters, triggers, etc.
It can actually be even simpler than that, as you can define your pipeline within Jenkins itself, however this doesn’t offer many of the advantages mentioned above.
The following is an example pipeline, which clones the repository associated with the pipeline, runs a linter, and executes some tests. Note that for demonstration purposes I’m using Tox, but any build tool or test harness could be used:
stage('Checkout') {
node {
deleteDir()
checkout scm
stash 'workspace'
}
}
stage('Lint') {
node {
deleteDir()
unstash 'workspace'
sh 'tox -e flake8'
}
}
stage('Test') {
node {
deleteDir()
unstash 'workspace'
sh 'tox -e tests'
}
}
In the above example, each node will independently queue for an executor in
Jenkins, whereas a traditional Jenkins job would run on a single executor. I’ve
found it to be a good practice to wipe out the workspace for every node
instance so that you start from a known state, and stashing/unstashing the
contents of the project prevent you needing to clone from a remote location
multiple times.
The above example would then display each stage as a column, such as:
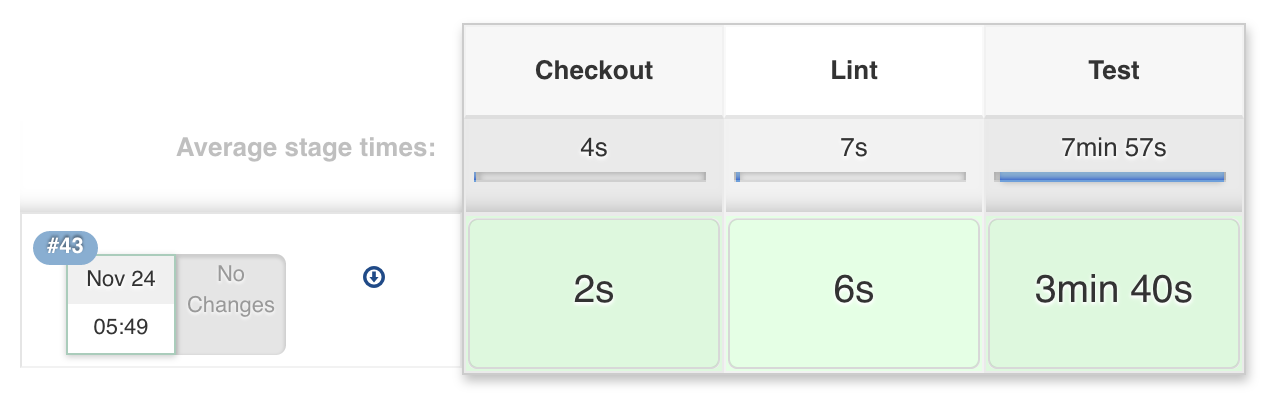
Issues encountered
As mentioned above, I’ve encountered a number of rough edges. Pipelines are in active development, and I expect them to become much more stable and easier to use in the coming months. Here’s some of the limitations I’ve encountered, and issues I’ve had to overcome:
-
Pipelines are not true Groovy - As I understand it, pipelines need to be restartable and therefore everything must be able to be serialised at any moment. For this reason, pipeline uses Groovy CPS, (continuous passing style), and as a result there are some Groovy features that are not available. I encountered this when attempting to iterate through items in a map. I suspect for many (especially with Groovy experience), this will be a particularly challenging issue. Hopefully future releases will bring Groovy CPS closer to native Groovy.
-
Limited plugin support - Only a subset of plugins have explicit pipeline support. In most cases this just means that there’s no convenient domain-specific language for the plugin, and therefore it might be necessary to invoke a plugin by its Java class name, which isn’t pretty (or user friendly).
-
No support for post-build steps - There isn’t currently any support for steps that run after your build, which means these steps need to be part of your pipeline. While that doesn’t sound too bad, you might want these steps to take into account the result of the build, or perhaps even to run regardless of the build result. By default a pipeline will exit on the first exception. If you want to send a notification on build failure, or publish your results somewhere, you need to wrap parts of your pipeline in try/catch/finally blocks. This adds complexity and harms the maintainability of your pipeline. Fortunately, this will be addressed by the Pipeline Model Definition plugin, which is currently in beta.
-
Test results for parallel steps are merged - If you run the same suite of tests against multiple environments, such as tests running in Firefox and Chrome, the JUnit test results are combined into a single report. This makes it difficult to identify the environment on which test failures occur, as the package structure is often identical for all suites.
-
Silent failures - This one is a killer. If your pipeline throws exceptions, it isn’t always obvious what the problem is. This is particularly problematic if you have try/except blocks to workaround the lack of post-build steps.
-
Syntax errors are common - Maybe it’s just me, but I’ve made a lot of syntax errors while working on pipelines. When this happens you either get a single exception, or a silent failure (see above). Ideally there would be some way to identify these issues earlier - perhaps as a pre-commit hook, or something in the Jenkins web console.
-
Scripts may need approval - The pipelines execute in a sandbox, and only those considered safe are allowed to be executed. One of the ways safety is checked is via a whitelist of approved operations. I encountered an issue where a safe operation was not in the whitelist, and I had to approve the script in the administrative interface. I reported this, and the whitelist was updated, but I suspect there may be more operations considered safe that could be added to this list. You can read more about this on the Script Security plugin page.
Overcoming issues
I developed a few practices when dealing with the above issues, which I’ve shared here:
-
Read the documentation - Let’s start with an obvious one. There’s some great documentation on pipelines, and many examples. It can be a little difficult to find what you need, and as pipelines are in active development you may encounter difficult styles or references to deprecated steps. I recommend persevering, and remember that Jenkins is an open source project. If you find issues with the documentation, there’s a great opportunity for you to make improvements so others don’t face the same struggle.
-
Trial and error - If at first your pipeline doesn’t work; try, try, try again. It’s frustrating, but sometimes you’ll just have to try small changes, commenting out sections, and adding echo steps to work out what’s going wrong. To save your sanity I suggest creating minimal pipelines that don’t use a remote repository so that you can rapidly try out new ideas and approaches. I also recommend getting Jenkins running locally (so you’re not waiting on network latency).
-
Replay pipelines - Another really handy feature is the ‘Replay’, which you will find on the left of a pipeline build page. This takes the pipeline that was executed for that build, but allows you to edit it before running it again. Be warned that you can lose your changes if you introduce a syntax error during a replay. I’ve also forgotten I was using replay, and only later realised why my changes didn’t persist.
-
Pipeline snippet generator - Within a pipeline page in Jenkins there’s a ‘Pipeline Syntax’ left on the left. This takes you to a snippet generator, which can be very useful if you’re struggling with the domain-specific language.
-
Ask for help - The Jenkins community is awesome, and many of them are in #jenkins on Freenode. There’s also a number of mailing lists.
-
Raise/vote/watch issues - If you encounter an issue, see if it’s been raised in the issue tracker. If you find a match, vote for the issue to help indicate how many users are affected. You can also watch the issue so you get notified of any activity. If you don’t find you issue, raise it with details of your environment and steps to reproduce. Remember, the more detail, the better the chance of the issue being fixed.
Coming soon
There are a few things coming soon to pipelines that are rather exciting. Some of these are already available in beta.
- New user interface - Blue Ocean is a beautiful redesign of the user interface for viewing jobs, and it’s already available (in beta) as a plugin. This really makes your pipelines stand out, and I’m particularly excited about how stages with parallel steps look:
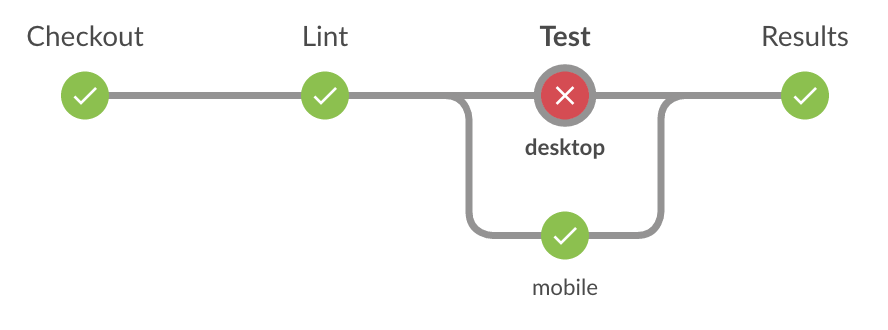
-
Declarative pipelines - The Pipeline Model Definition plugin redefines the pipeline syntax, and adds more power to configuration as code. The new pipeline model definition allows for more control of the build environment, defining environment variables, post-build steps such as reporting test results and storing artefacts or notifications, and much more. This is also already available in beta, though recent releases have had backwards-incompatible changes, so I’d recommend waiting for things to stabilise.
-
Pipeline editor - It’s not clear how far off it is, but there is a neat looking Pipeline Editor plugin in development. Personally I prefer to craft scripts purely in a text editor, but I do this the visuals in the screenshots look great and this would certainly make pipelines more accessible.
-
Pipeline linter - I couldn’t find anything on this, but I believe I’ve heard that there’s been some work on a pipeline linter. This would be awesome to prevent the save->run->review cycle for simple syntax issues that could be caught earlier.
Conclusion
Jenkins pipelines are incredibly powerful and raise the status of your jobs to the same level as your application code. I would certainly recommend looking into replacing your traditional jobs with pipelines, and if you’re entirely new to Jenkins you should definitely start with pipelines. That said, you may encounter some frustrating issues. If this stops you from adopting pipelines, I would encourage you raise or vote on those issues and to check back every few months.